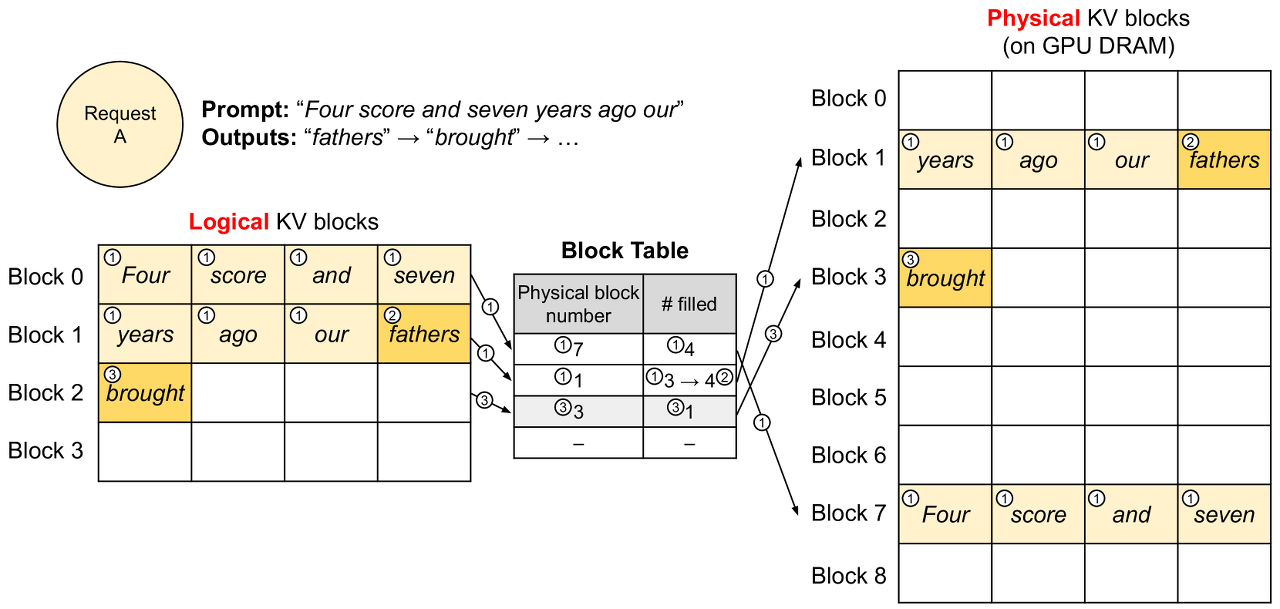
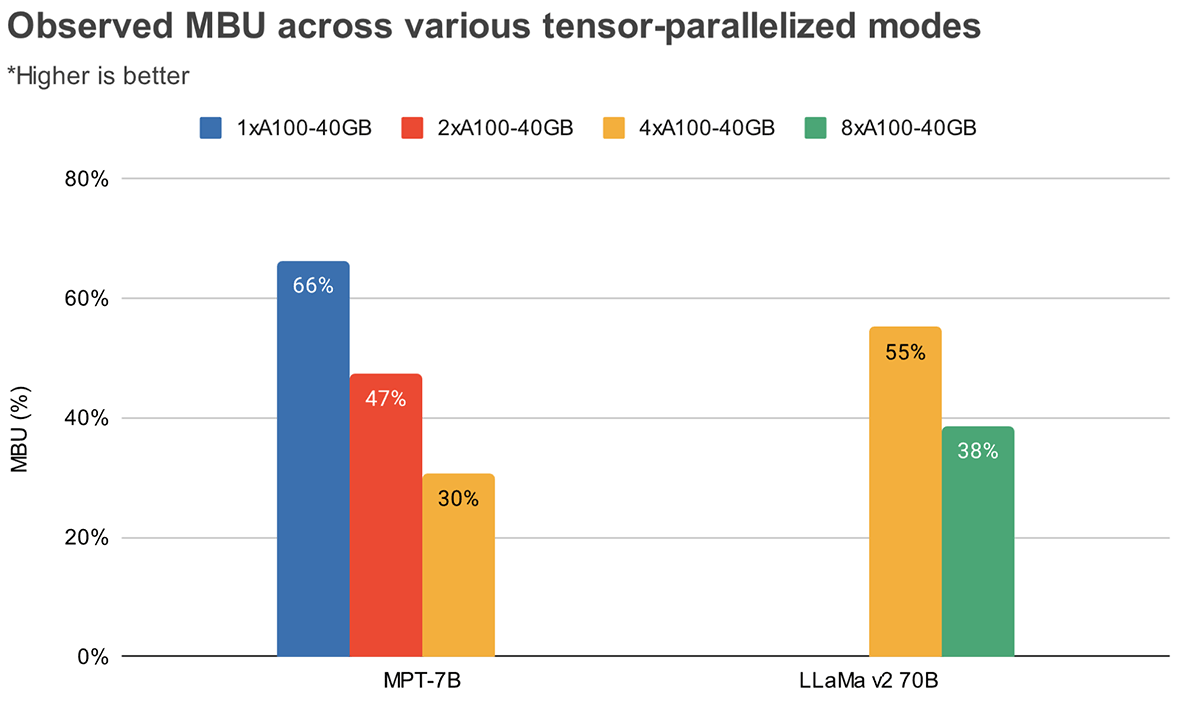
∈https://huggingface.co/blog/optimize-llm Optimizing your LLM in production Optimizing your LLM in production Note: This blog post is also available as a documentation page on Transformers. Large Language Models (LLMs) such as GPT3/4, Falcon, and LLama are rapidly advancing in their ability to tackle human-centric tasks, establish huggingface.co 효율적인 LLM deployment를 위해 가장 효과적인 기술 Lower Precision..