MBU 정의
MBU(Model Bandwidth Utilizaiton)는 HW utilizaiton을 측정하기 위한 새로운 metric
MBU가 100% 에 근접할수록 시스템의 가용 BW를 제대로 활용하는 것임
MPU = (achieved memory bandwidth) / (peak memory bandwidth)
- achieved memory bandwidth = ((total model parameter size) + KV cache size)/TPOT
- TPOT(Time Per Output Token)
예제) 7B model with 16bit precision, KV cache size는 무시, TPOT=14 ms/token, memory bandwidth=2TB/sec
MPU = (14GB/14 ms)/2TB/sec = (1TB/sec)/(2TB/sec) = 50%
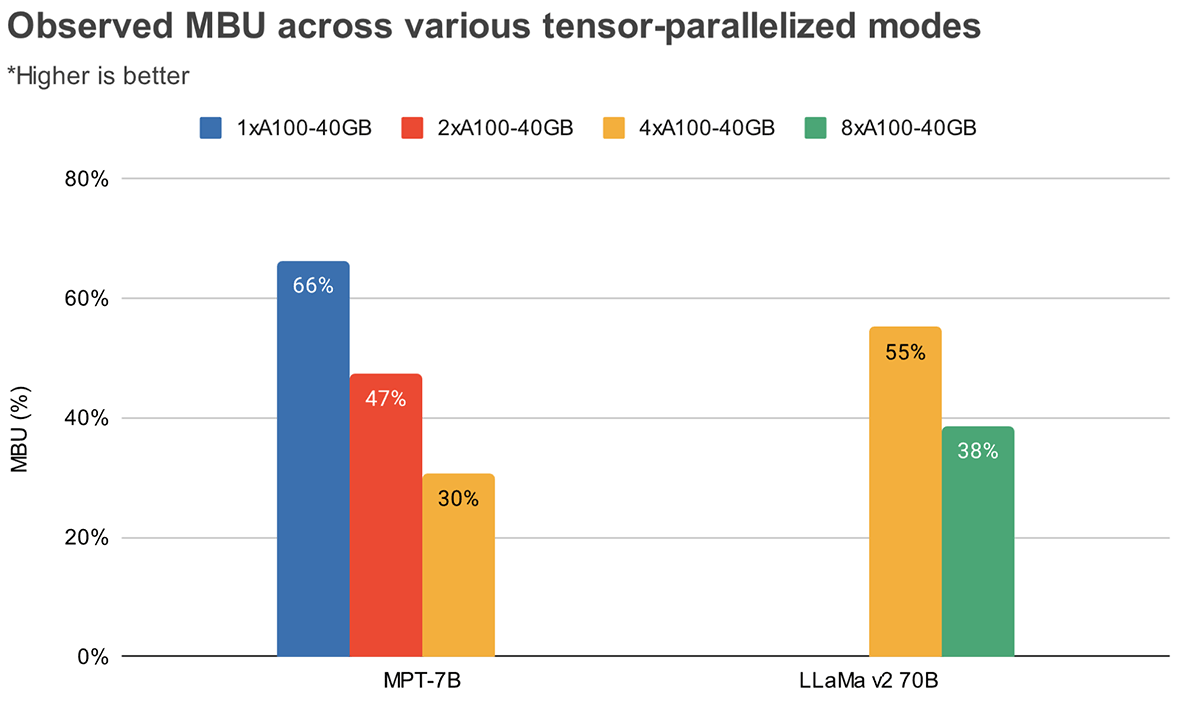
Tensor Parallelism 수준별 MBU
Peak memory bandwidth utilization은 연속된 대용량 메모리 청크를 전송할 때 달성됨
MPT-7B와 같은 작은 모델은 Tensor Parallelism 수준이 깊어질수록 MBU가 낮아지는 이유임
4-way Tensor Parallelism 조건에서 파라미터 크기가 큰 모델(LLaMa v2 70B)의 MBU가 더 큼 (LLaMA v2 70B 55% > MPT-7B: 30%)
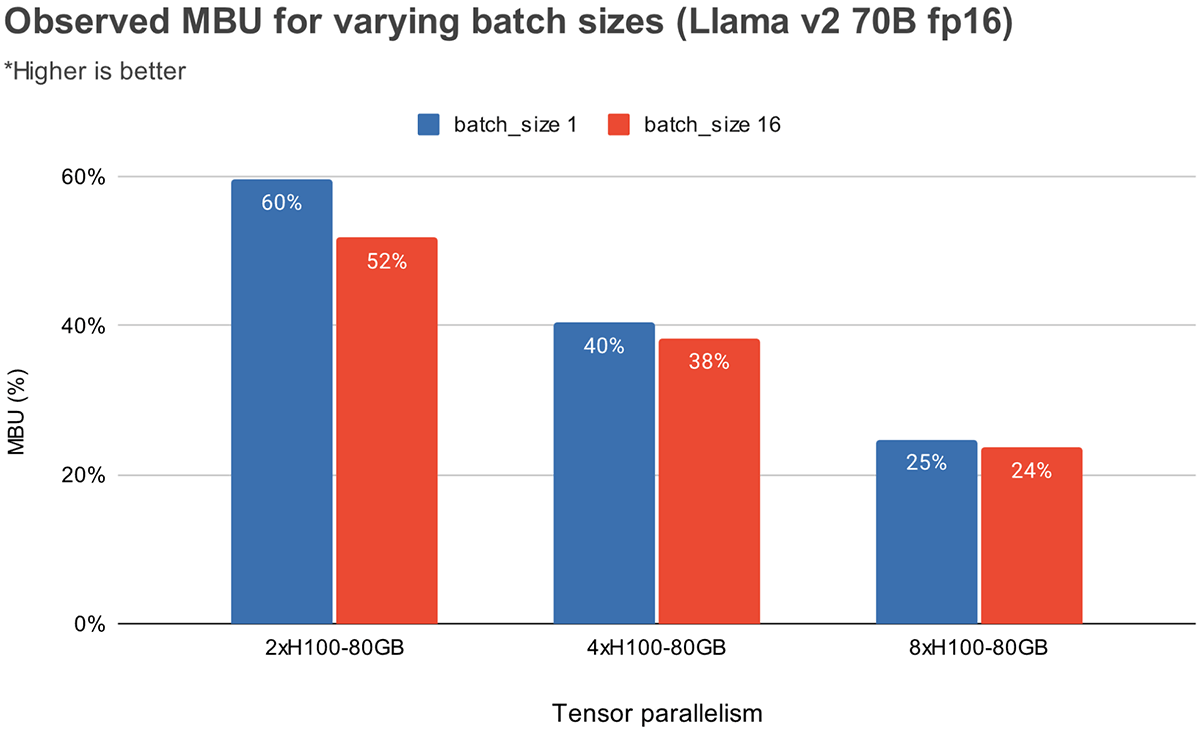
배치 사이즈별 MPU
배치 사이즈가 증가할수록 MBU가 감소함. 하지만 Tensor Parallelism이 깊어질수록 MBU의 상대적 감소는 덜 두드러짐
- 2-way TP : 60%@bs=1 → 52%@bs=16 (-8%)
- 4-way TP : 40%@bs=1 → 38%@bs=16 (-2%)
- 8-way TP : 25%@bs=1 → 24%@bs=16 (-1%)
(그 이유는..? 좀더 생각이 필요함)
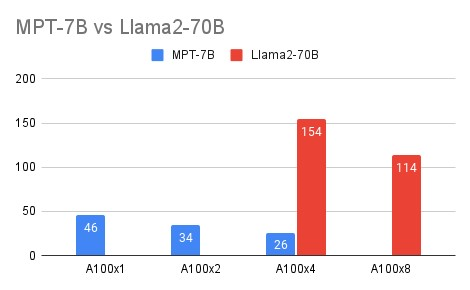
메모리 대역폭이 더 큰 하드웨어를 선택하면 더 적은 수의 GPU로 성능을 향상시킬 수 있음
예를들어 동일한 batch size = 1 에서
- 60%@2xH100(80GB) : aggregation BW = 3.35TB/s * 2 = 6.7TB/s → 6.7TB/s*0.6 = 4.02TB/s
- 55%@4xA100(40GB) : aggregation BW = 2TB/s * 4 = 8TB/s → 8TB/s*0.55 = 4.4TB/s
Latency 측정 결과
TTFT(Time To First Token)
모델 학습과 달리, 더 많은 GPU로 확장하면 추론 latency는 크게 감소함
- Tensor Parallelism 수준이 더 높아질수록 MBU는 더 낮아짐
- Tensor Parallelism는 GPU 노드 전체에 통신 오버헤드를 유발함
- batch size=1 → 16으로 높아지면 TTFT는 커질 것으로 생각됨
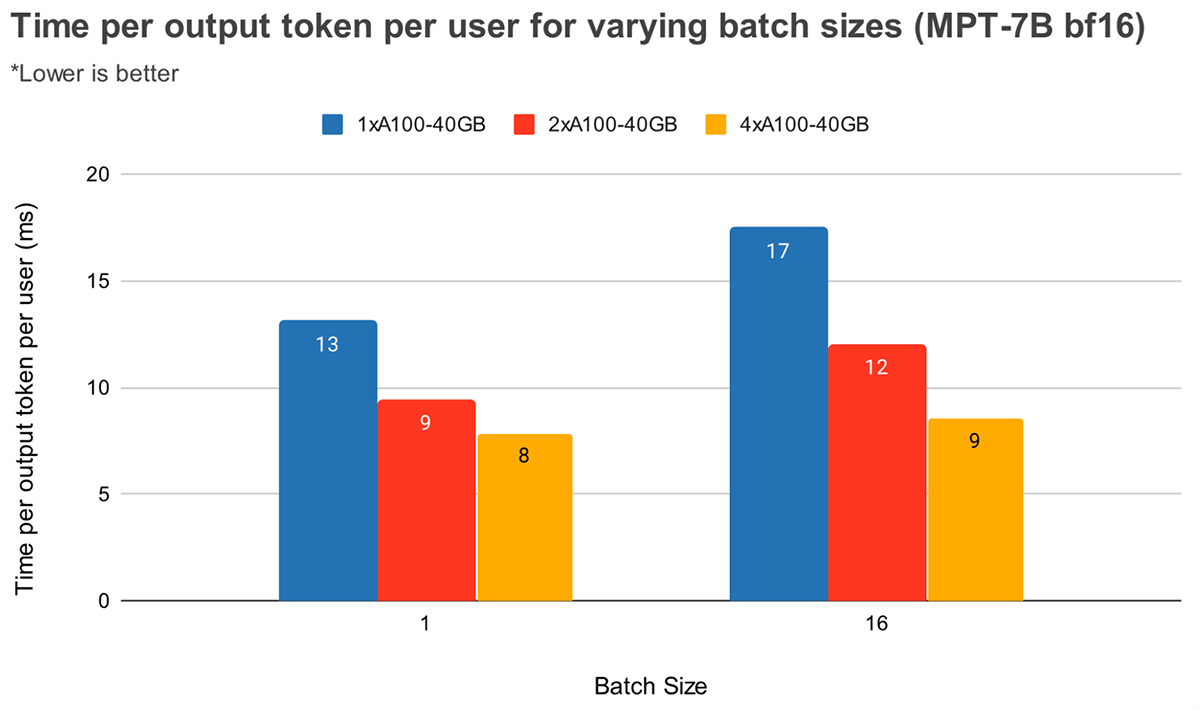
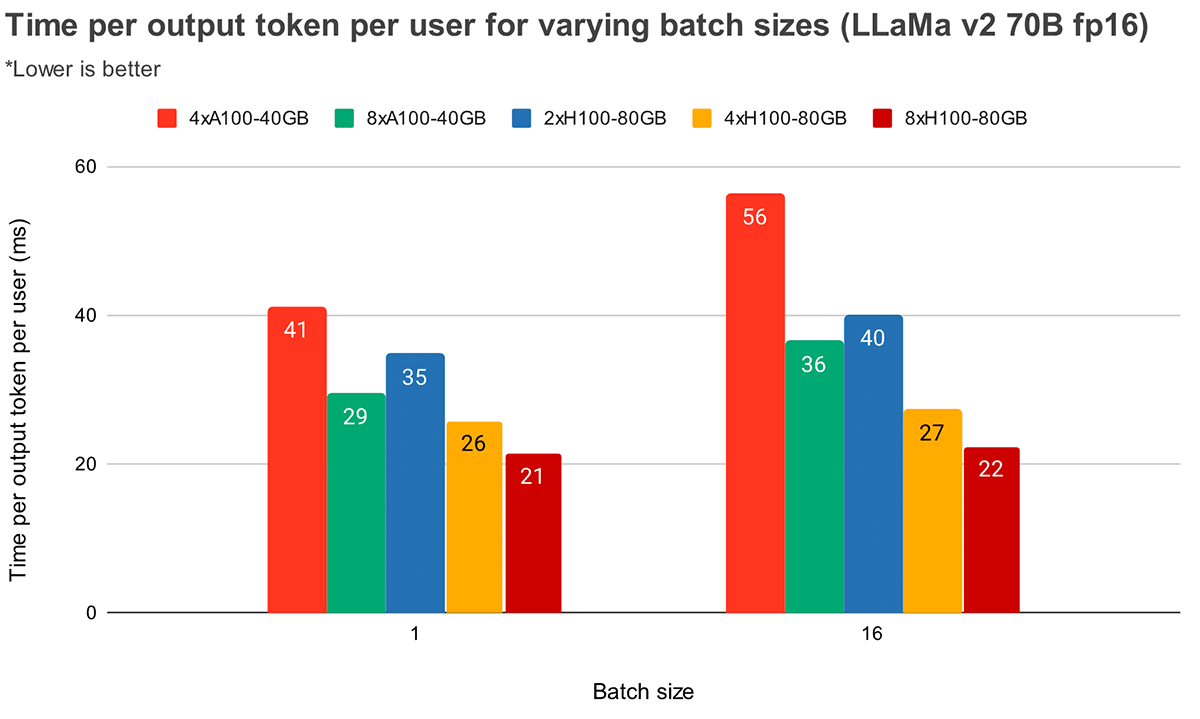
Time Per Output Token (MPT-7B)
큰 batch size에서 Tensor Parallelism 수준이 높을수록 토큰 latency가 상대적으로 더 크게 감소함
큰 batch size에서 Tensor Parallelism 수준이 높을수록 MBU의 상대적인 감소가 더 작다라는 앞선 관찰 결과와 일치함
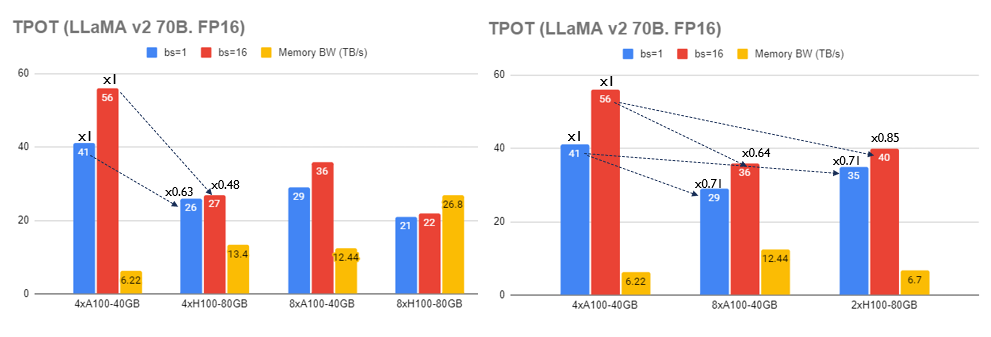
Time Per Output Token (LLaMA v2 70B)
- 4xA100-40GB vs 4xH100-80GB
- batch size가 클수록(bs=16) aggregated Memory BW가 2배가 될 때 TPOT가 1/2로 줄어듬 (56ms → 27ms)
- FLOPS보다 Memory BW(A100-40GB:1.55TB/s vs H100-80GB:3.35TB/s)가 더 중요함을 알 수 있음
- Aggregated Memory BW: 6.22GB/s@4xA100-40GB
- Aggregated Memory BW: 13.4GB/s@4xH100-80GB
- 4xA100-40GB vs 2xH100-80GB
- 동일한 aggregated Memory BW이라면 Tensor Parallelism 수준이 낮을수록 TPOT가 더 낮음
- 41ms, bs=1@4xA100-40GB(aggregated memory BW = 6.22TB/s)
- 35ms, bs=1@2xH100-80GB(aggregated memory BW = 6.70TB/s)
- 동등한 TPOT의 경우, batch size가 높고 Tensor Parallelism 수준이 낮을 때 높은 throughput을 보임
- 41ms, bs=1@4xA100-40GB
- A100x4의 FLOPS = 312*4 = 1248 FLOPS (FP16)
- 40ms, bs=16@2xH100-80GB
- H100x4의 FLOPS = 989*2 = 1978 FLOPS (FP16)
- 41ms, bs=1@4xA100-40GB
- TPOT는 generation 연산과 연관되므로 memory-bound임.
- FLOPS보다 Aggregated Memory BW에 더 많은 영향을 받음
- 4xA100-40GB를 2xH100-80GB로 변경하는 것이 8xA100-40GB로 변경하는 것보다 더 cost-efficiency함
- H100x2 = $30,000*2 = $60,000
- A100x8 = $10,000*8 = $80,000
- 동일한 aggregated Memory BW이라면 Tensor Parallelism 수준이 낮을수록 TPOT가 더 낮음
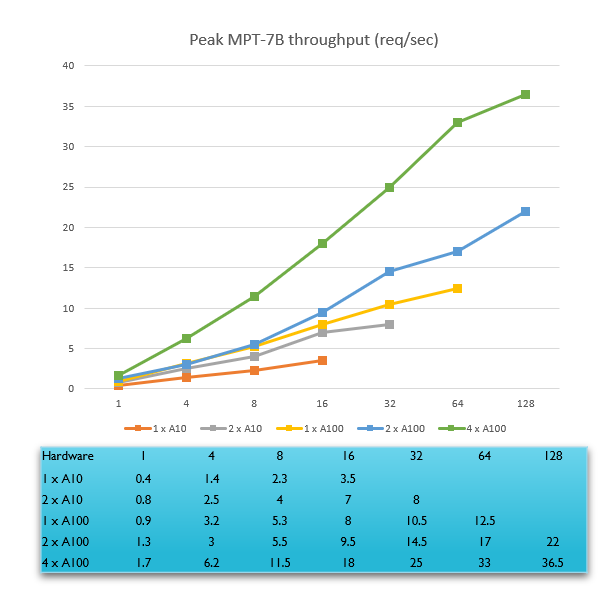
Batch Size
Static batching 시 Batch Size별 Peak MPT-7B throughput (req/sec)
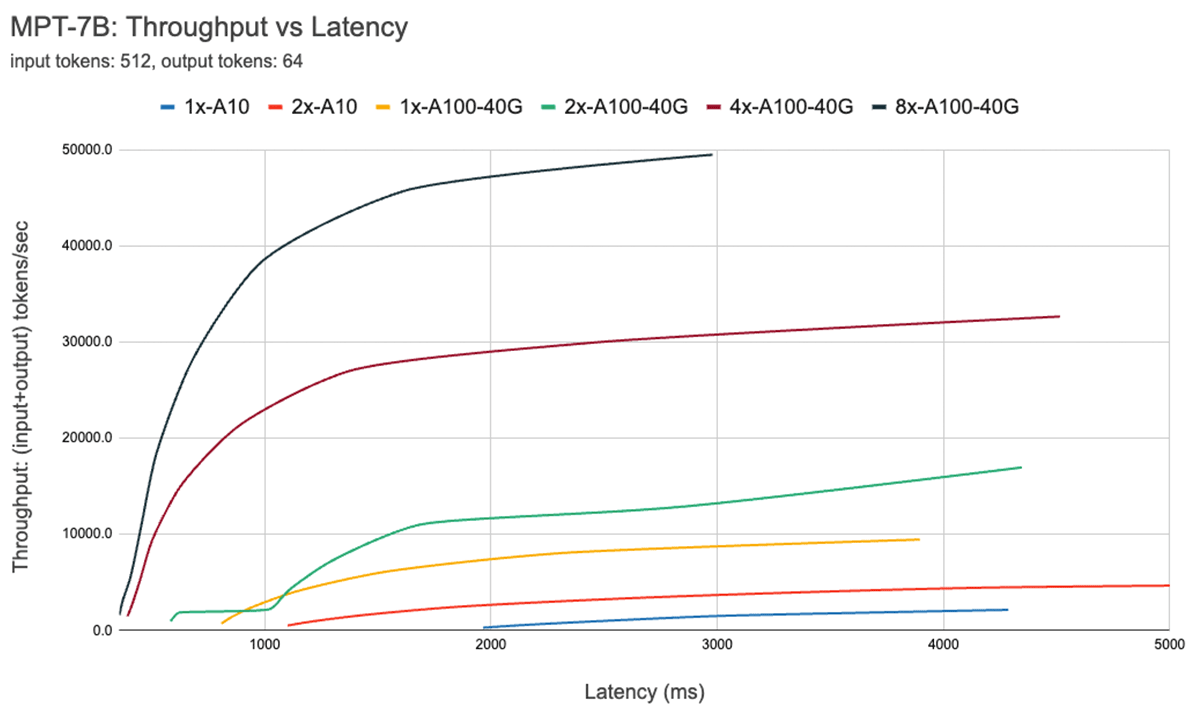
Latency Trade-Off
아래 곡선은 MPT-7B의 throughput 대 latency 곡선을 보여줌.
- Request latency는 batch size에 따라 증가함
- 예를들어 batch size = 1 → 64로 증가시켰을 때, latency는 x4, throughput는 x14로 증가함
- 특정 배치 크기 이후, compute-bound 영역으로 넘어가면 batch size를 두배로 늘릴 때마다 throughput은 증가하지 않고 latency만 증가함
자체 모델을 호스팅하는 사용자는 애플리케이션에 적합한 latency/throughput 절충안을 결정해야 함
- 챗봇은 짧은 응답 latency가 최우선
- 비정형 PDF의 일괄적 처리는 모든 문서를 병렬로 빠르게 처리하기 위해 개별 문서 처리 latency 시간을 희생해야 함
Parallelism을 사용할 때 low-level HW의 details들을 잘 알아야 함
- Cloud 중에는 모든 GPU가 high BW로 연결된 서버가 있는 반면 2개의 GPU(1-pair)씩 high BW(NVLINK)로 연결되어 있지만 1-pair는 low BW(PCIe)로 연결된 서버가 있을 수 있음
레퍼런스
https://www.databricks.com/blog/llm-inference-performance-engineering-best-practices
LLM Inference Performance Engineering: Best Practices
In this blog post, t
www.databricks.com
'Daily-Trend-Review' 카테고리의 다른 글
| 좋은 개발 리더 되기 (0) | 2023.11.29 |
|---|---|
| 2023/11/13: S-Lora 등 (0) | 2023.11.13 |
| 2023/11/11: Sliding Window Attention(SWA) 메커니즘 (0) | 2023.11.11 |
| 2023/10/27: transformer-math (0) | 2023.10.27 |
| 2023/10/24: attention (0) | 2023.10.24 |