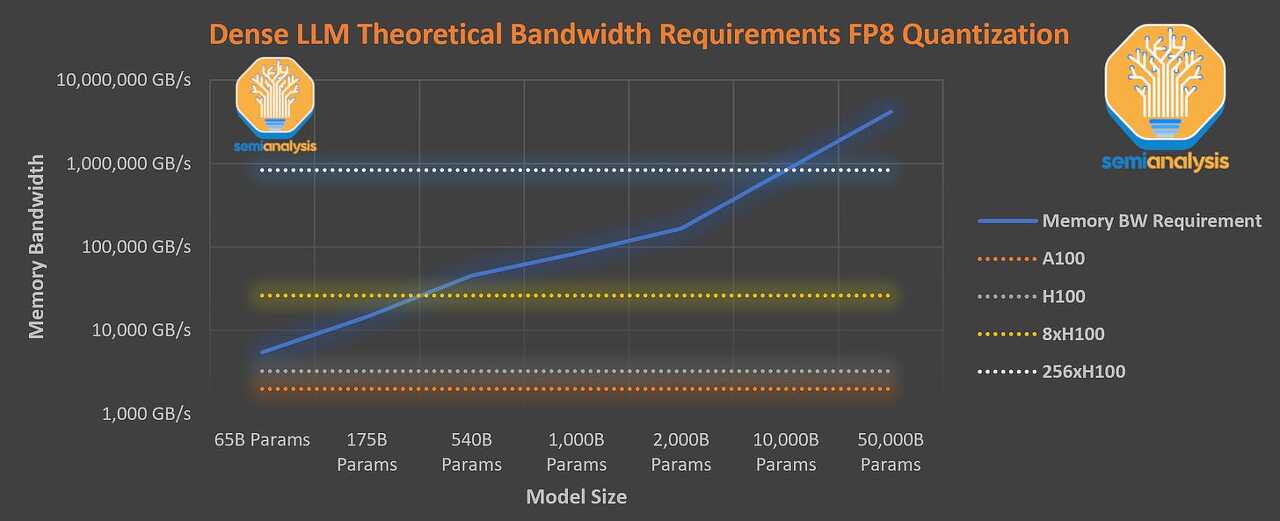
Large Language Models - the hardware connection LLM inference - HW/SW optimizations HOW TO BUILD LOW-COST NETWORKS FOR LARGE LANGUAGE MODELS (WITHOUT SACRIFICING PERFORMANCE)? Reducintg Activation Recomputation in Large Trnasformer Models Attention Block Q, K, V matrix multiplies 2sbh 11sbh + 5as2b QKT 4sbh Softmax 2as2b Softmax dropout as2b Attention over Values(V) 2as2b(dropout output)+2sbh(Va..