https://a16z.com/2023/06/20/emerging-architectures-for-llm-applications/
Emerging Architectures for LLM Applications | Andreessen Horowitz
A reference architecture for the LLM app stack. It shows the most common systems, tools, and design patterns used by AI startups and tech companies.
a16z.com

디자인 패턴: In-Context Learning
- In-Context Learning의 핵심 아이디어
- Fine-tuning 없이 LLMs를 사용
- 대신 개인 컨텍스트 데이터에 대한 영리한 프롬프트 및 조건을 통해 행동을 제어하는 것
- 예) 법률 문서에 대한 질문에 답하기 위해 챗봇을 구축한다라고 가정
- 나이브한 접근 방식
- 모든 문서를 ChatGPT 또는 GPT-4 프롬프트에 붙인 다음 질문함
- GPT-4는 최대 50 페이지 (32K tokens) 정도의 입력만을 처리 가능
- 성능(추론 시간 및 정확도)이 Context Window의 제한에 접근함에 따라 심하게 저하됨
- 영리한 접근 방식
- In-Context Learning은 LLM 프롬프트에 모든 문서를 보내는 대신 가장 관련성이 높은 소수의 문서만을 보냄
- 나이브한 접근 방식
- In-Context Learning의 장점
- LLM 자체를 훈련하거나 fine-tuning하는 것보다 쉬움
- 전문화된 ML 엔지니어 팀을 필요로로 하지 않음
- 자체 인프라를 호스팅하거나 OpenAI에서 값비싼 전용 인스턴스를 구입할 필요가 없음
- 특정 정보가 학습 데이터셋에서 최소 10회 이상 발생해야 LLM이 fine-tuning을 통해 이를 기억할 수 있음
- 반면, In-Context Learning은 상대적으로 작은 데이터셋으로 fine-tuning보다 더 우수한 성능을 발휘하는 경향이 있음
- In-Context Learning에서 Context Window 사이즈 늘리기
- 프롬프트 길이에 따라 추론 비용과 시간이 2차식으로 스케일됨
- 10K 페이지가 넘는 단일 GPT-4 쿼리는 현재 API 요금으로 수백 달러의 비용이 소요됨
- In-Context Learning의 workflow
- 데이터 전처리/임베딩
- 프롬프트 구성/검색
- 프롬프트 실행/추론
Data Preprocessing/Embedding
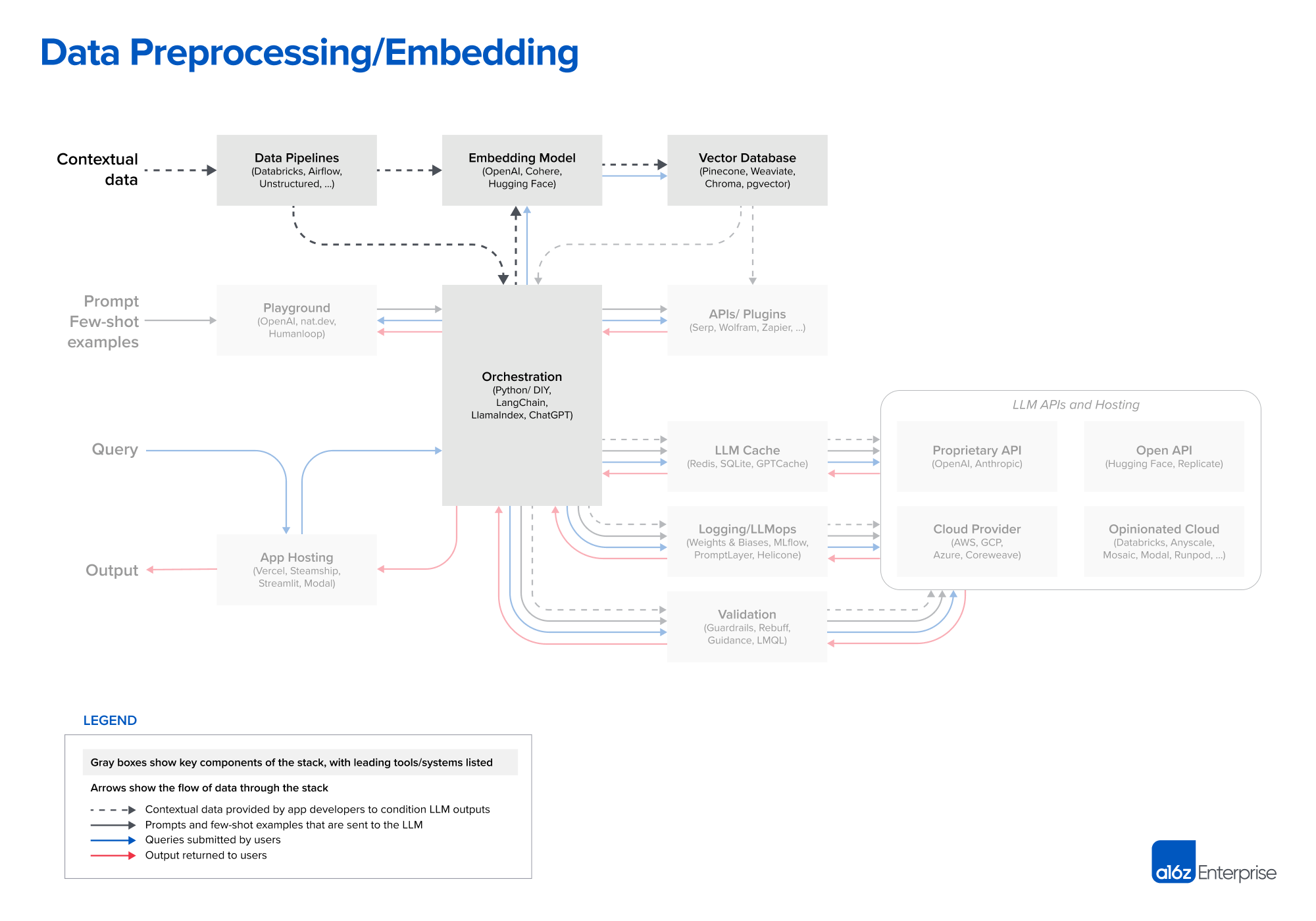
- LLM 앱의 컨텍스트 데이터
- 텍스트 문서, PDF, CSV, SQL 테이블과 같은 구조화된 형식도 포함
- 데이터 로딩 및 변환 솔루션
- Databricks 또는 Airflow와 같은 기존 ETL 도구를 사용
- LangChain 및 LlamaIndex와 오케스트레이션 프레임워크의 내장 문서 로더
- 관련 스택이 덜 개발되었다고 판단. LLM 앱용으로 제작된 데이터 복제 솔루션에 기회가 있음
- 임베딩
- 대부분의 개발자들은 text-embedding-ada-002 모델과 같은 OpenAI API을 사용
- 일부 대기업은 특정 시나리오에서 더 나은 임베딩 성능을 제공하는 cohere를 탐색 중
- 오픈소스에서는 Hugging Face의 Sentence Transformer 라이브러리가 표준
- 벡터 데이터베이스
- 시스템 관점에서 전처리 파이프라인의 가장 중요한 부분은 벡터 DB임
- 수십 억개의 임베딩을 효율적으로 저장, 비교, 검색하는 역할을 수행함
- 일반적인 선택은 pinecone
- 완벽하게 클라우드에 호스팅되어 시작하기 쉬우며 production에 필요한 많은 기능(e.g. 우수한 규모의 성능, SSO 및 가동 시간 SLA)를 갖추고 있음
- 기타 벡터 DB
- 오픈소스 (Weaviate, Vespa, Qdrant) → 맞춤형 플랫폼 구축을 선호하는 숙련된 AI 팀에 인기
- 로컬 벡터 관리 라이브러리 (Chroma 및 Faiss) →
- OLTP 확장 (pgvector) → 모든 DB 모양의 구멍을 찾아 Postgres를 삽입하려는 개발자, 대부분의 데이터 인프라를 단일 클라우드 제공업체로부터 구매하는 기업에게 좋은 솔루션
- 벡터 DB의 향후 발전 방향
- 대부분의 오픈소스 벡터 DB 회사는 클라우드 제품을 개발 중
- 클라우드에서 강력한 성능을 달성하는 것은 매우 어려워 장기적으로 옵션 세트가 변경될 가능성이 높음
- 벡터 DB는 OLTP 및 OLAP과 유사하므로 한두개의 널리 사용되는 시스템으로 통합될지 여부 모니터링 필요
- Context Window이 커짐에 따라 임베딩 및 벡터 DB가 어떻게 발전할지? Context Windows은 강력한 도구지만 상당한 계산 비용이 수반됨
Prompt Construction/Retrieval
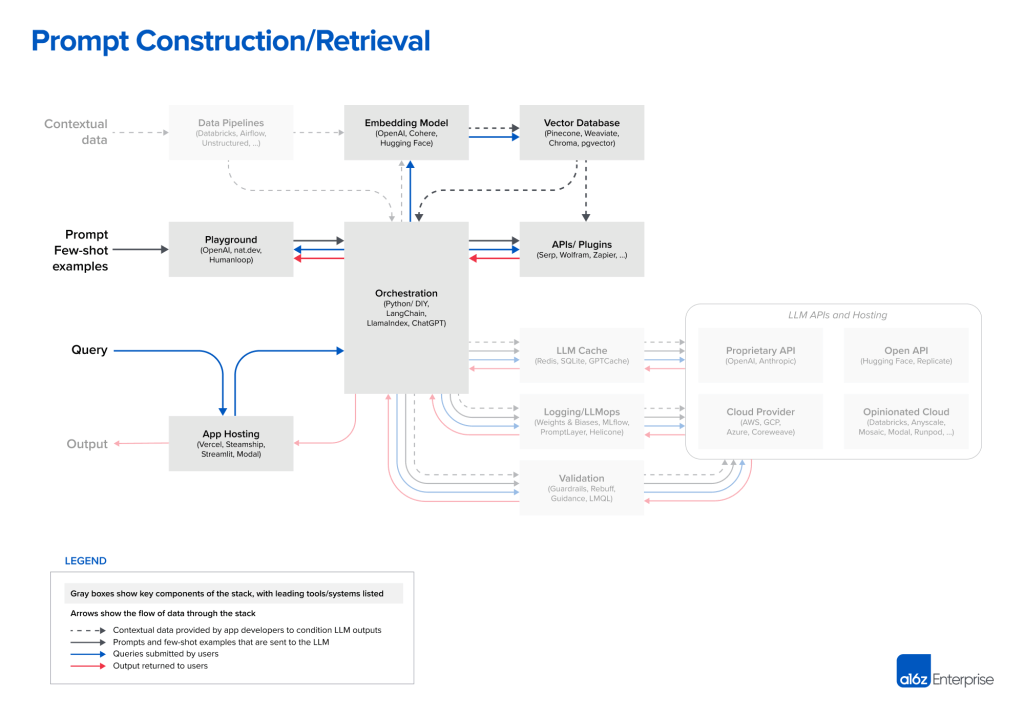
- Prompt Engineering의 중요성
- LLM을 유도하고 상황에 맞는 데이터를 통합하기 위한 전략은 점점 더 복잡해짐
- 제품 차별화의 원천으로서 점점 더 중요해지고 있음 → 이를 위해 프롬프트 엔지니어링 전략이 필요
- 프롬프트는 종종 좋은 결과를 제공하지만 때론 프로덕션 배포에 필요한 정확도 수준에 미치지 못함
- 오케스트레이션 프레임워크 (LangChain, LlamaIndex)
- 프롬프트 연결의 많은 세부 사항을 추상화함
- 외부 API와의 인터페이스
- 벡터 DB에서 컨텍스트 데이터 검색
- 여러 LLM 호출에 걸친 메모리 유지
- 선두주자는 LangChain
- LangChain은 새로운 프로젝트지만 이를 사용하여 빌드된 앱들이 제품화되는 것이 등장하기 사작함
- 일부 개발자는 종속성을 제거하기 위해 제품화에 native python을 선호하지만 시간이 지남에 따라 감소할 것으로 예상
- ChatGPT도 오케스트레이션?
- ChatGPT는 개발자 도구가 아닌 앱으로 오케스트레이션 프레임워크와 동일한 기능을 일부 수행함
- 맞춤형 프롬프트을 위한 필요성을 추상화
- 상태 유지
- 플러그인, APIs 또는 다른 소스를 통해 컨텍스트 데이터 검색
- 다른 오케스트레이션 프레임워크와 직접적인 경쟁자는 아니지만 대체 솔루션으로 간주됨
- ChatGPT는 개발자 도구가 아닌 앱으로 오케스트레이션 프레임워크와 동일한 기능을 일부 수행함
- 프롬프트 연결의 많은 세부 사항을 추상화함
Prompt Execution/Inference
- 제품화 및 규모가 커지면 더 다양한 옵션을 채택할 수 있음
- gpt-3.5-turbo로 전환
- GPT-4 보다 50배 저렴하고 훨씬 더 빠름
- 다른 독점 공급 업체(Anthropic의 Claude 모델)로 실험
- Claude는 빠른 추론, GPT-3.5수준의 정확도, 100K Context Window
- 오픈소스 모델로 일부 요청을 처리
- 검색이나 채팅과 같은 대용량 B2C 사용 사례에서 효과적
- 오픈소스 베이스 모델을 finetuning하는 것과 함계 사용할 때 가장 효과적임
- Databricks, Anyscale, Mosaic, Modal 및 RunPod와 같은 플랫폼 존재
- 오픈소스 모델을 사용 옵션
- Hugging Face 및 Replicate의 간단한 API 인터페이스
- 주요 클라우드 제공업체의 원시 컴퓨팅 리소스
- 위에 나열된 것과 같은 보다 전문적인 클라우드 제품 등
- gpt-3.5-turbo로 전환
- 오픈소스 모델의 성능 향상
- 독점 제품과 격차를 줄이고 있음
- Meta의 LLaMA 모델은 오픈 소스 정확도에 대한 새로운 기준을 설정하고 다양한 변형을 시작함
- LLaMA2는 진정한 오픈소스로 릴리즈될 가능성이 있음
- LLM을 위한 운영 도구
- LLM Caching
- 애플리케이션 응답시간과 비용을 개선하기 때문에 Redis 기반이 일반적임. 그밖에 SQLite, GPTCache
- Logging/LLMops
- 프롬프트 생성, 파이프라인 튜닝 또는 모델 선택을 개선하려는 목적으로 LLM 출력을 로깅,모니터링,평가하기 위한 툴
- Weights & Biases, MLflow, PromptLayer, Helicone
- Validation
- LLM 출력 검증(e.g. Guardrails)
- 프롬프트 인젝션 공격 감지(e.g. Rebuff)
- LLM Caching
- LLM App Hosting
- 가장 일반적인 솔루션은 Vercel 또는 주요 클라우드 공급자와 같은 표준 옵션
- Hosting 스타트업
- Steamship: 오케스트레이션(LangChain), 다중 tenant 데이터 컨텍스트, 비동기 작업, 벡터 스토리지 및 키 관리를 포함한 LLM 앱을 위한 E2E 호스팅을 제공함
- 그밖에 Anyscale 및 Modal과 같은 회사를 통해 개발자는 모델과 Python 코드를 한 곳에서 호스팅할 수 있음
'Daily-Trend-Review' 카테고리의 다른 글
| 2023/07/07: SW 애플리케이션에서 대규모 언어모델 활용 (0) | 2023.07.07 |
|---|---|
| 2023/07/06: Vector DB, Transformer, Context Window, vLLM 등 (0) | 2023.07.06 |
| 2023/06/22: Generative AI 등 (0) | 2023.06.22 |
| 2023/05/29: State of GPT, Voyager, LLaMA-Adapter 등 (0) | 2023.05.29 |
| 2023/05/25: 학습 flops 평가, 무한 외부 메모리를 가진 ChatGPT 등 (0) | 2023.05.25 |