1. How Nvidia’s CUDA Monopoly In Machine Learning Is Breaking - OpenAI Triton And PyTorch 2.0
source: https://www.semianalysis.com/p/nvidiaopenaitritonpytorch#%C2%A7machine-learning-training-components
Pytorch vs Tensorflow
- Pytorch가 승리한 이유
- Pytorch는 eager 모드를 지원
- 한줄씩 실행하므로 중간 작업의 결과를 보고 모델이 어떻게 동작하는지 확인 가능하여 코드 디버깅이 용이하였음
- TF는 graph 모드를 지원
- graph 모드는 1) 계산 그래프 정의 2) 계산 그래프 실행으로 동작
- 실행이 끝날 때까지 무슨 일이 일어나고 있는지 알 수 없기 때문에 코드 디버깅이 어려움
- Pytorch는 eager 모드를 지원
- Generatvie AI 모델은 대부분은 Pytorch 기반. 구글은 TF 대신 JAX를 기반으로 함
Machine Learning Training Components
- ML 학습 시간은 두가지 시간 구성요소가 있음
- 컴퓨팅 (FLOPS): 각 layer 이내 Dense Matrix Multiplication
- 메모리 (Bandwidth) : BW-constrained ops 사례 (Nomalization, pointwise ops, SoftMax, ReLU)
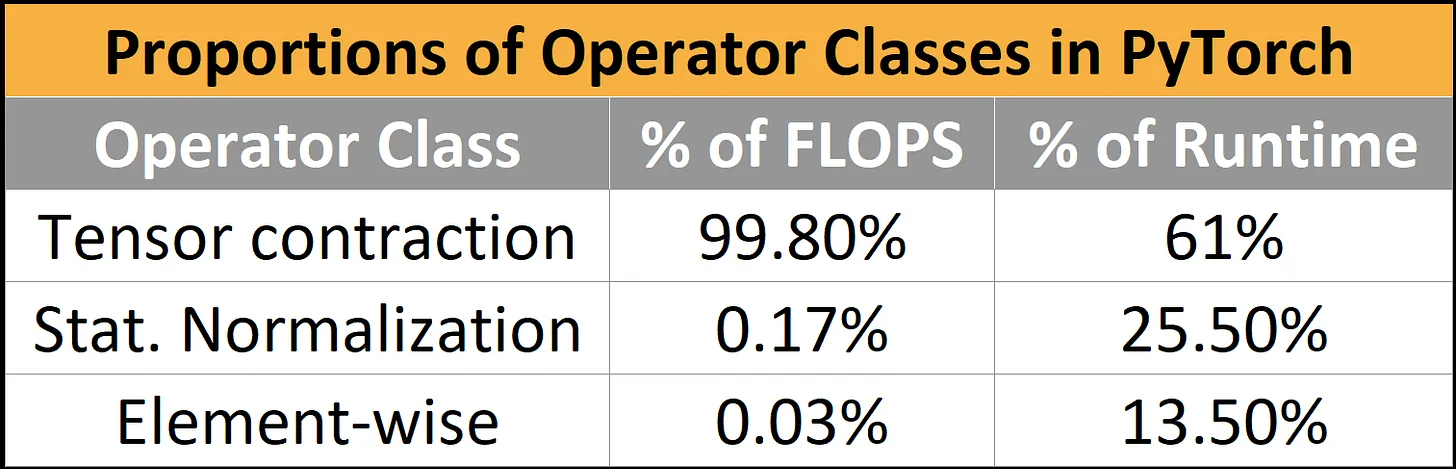
- BERT 실행 시간 분석
- 컴퓨팅 바인딩 워크로드가 99.8%였지만 실제 런타임은 61%에 불과함
- Normalization과 Element-wise 연산은 0.2%w를 차지하지만 39%의 시간을 소비함
Memory Wall
- 대규모 모델 학습/추론에서 행렬 곱을 계산하는데 소비되는 것이 아니라 데이터가 컴퓨팅 리소스에 도달하는데 소비됨
- 메모리 계층 중 SRAM이 프로세서와 가장 가깝지만 SRAM을 사용하는 것은 한계가 있음 (Cerebras도 40GB에 불과함)
- GPU의 SRAM 용량 문제
- A100: 40GB, H100: 50GB
- TSMC의 5nm 공정 노드에서 1GB SRAM은 200mm^2가 필요함.
- on-chip SRAM의 GB당 비용은 5nm보다 3nm보다 실제 더 비쌈
- DRAM 문제
- DRAM은 전체 서버 비용의 50%를 차지함
- GPU에 사용되는 HBM는 GB당 10~20$임
- 메모리 대역폭과 용량 베약으로 인해 A100의 FLOPS 활용도가 매우 낮음
- 최적화에도 불구하고 60% FLOPS 활용도는 LLM 학습에서 굉장히 높은 수준의 utilization으로 간주됨
- A100에서 H100으로 발전할 때 FLOPS는 6배 증가하지만 메모리 BW는 1.65배 증가에 그쳐 이를 극복하기 위한 trick이 필요함
Operation Fusions
- Eager 모드는 실행할 때 operation마다 메모리 read/write를 발생하므로 메모리 대역폭을 크게 증가시킴
- 이를 해결하기 위한 주요 최적화로 operation fusions을 많이 사용함
- Opearation fusion을 이용하면 중간 결과를 메모리에 쓰는 대신 여러 함수가 한번에 계산되기 때문에 메모리 read/write를 최소화함
- CUDA로 직접 구현할 수 있지만 Pytorch 내 점점 더 많은 operation fusion 연산자들이 많아져 eager 모드의 성능이 더 빨라졌음
- 하지만 단점으로 몇년동안 operators가 2천개 이상의 증가함
Nvidia가 왕
- ML 칩을 개발하는 모든 사람들은 동일한 Memory Wall에 걸림
- 거기에 ASIC은 NVIDIA GPU에 최적화된 Pytorch에 맞춰 개발할 수 밖에 없음
- 즉, 기존에 GPU 최적화된 Pytorch를 ASIC에 맞추는 것은 매우 어려운 일
- NVIDIA GPU에 최적화된 모델을 다른 HW로 원활하게 migration하는 방법
- Pytorch 2.0, OpenAI Triton, MosaicML과 같은 MLOps 회사가 HW 추상화를 진행시킨다면 칩솔루션의 아키텍처와 경제성이 사용편의성보다 더 큰 구매 동인으로 작용할 것으로 전망
Pytorch 2.0
- Pytorch 2.0은 graph 모드 실행을 지원하는 컴파일 솔루션이 추가되어 다양한 HW 리소스를 지원하기 좋아짐
- DP, Sharding, Pipeline Parallelism 및 Tensor Parallelism에 대한 더 나은 API 지원으로 분산 학습을 개선함
- LLM의 다양한 시퀀스 길이를 훨씬 쉽게 지원할 수 있음
- 신기술: TorchDynamo, AOTAutograd, PrimTorch, TorchInductor
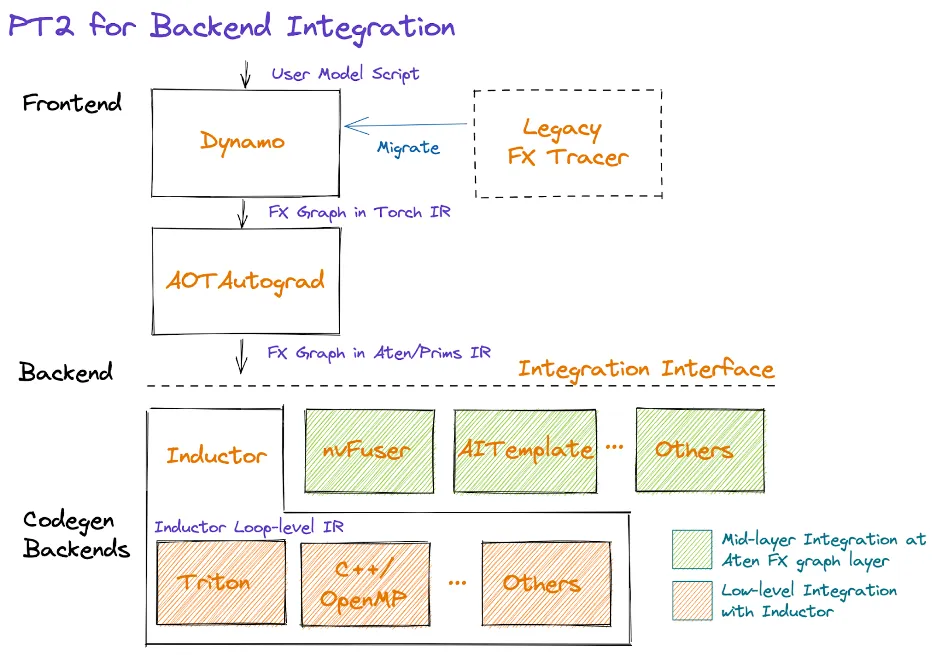
OpenAI Triton
- Triton은 입력을 LLVM IR로 변환한 후 NVIDIA GPU의 경우, PTX 코드를 직접 생성함.
- Triton은 상위수준 언어로 하위수준 언어(CUDA)과 비슷한 성능을 달성할 수 있음
- Triton은 일반적인 ML 연구원들이 쉽게 읽을 수 있어 유용성이 큼
- 여타 HW 가속기를 Triton의 일부인 LLVM IR에 직접 통합할 수 있는 기능은 새로운 HW를 위한 AI 컴파일러 스택을 구축하는 시간을 크게 줄임
'Daily-Trend-Review' 카테고리의 다른 글
| 2023/03/06: LLaMA, OpenAI ChatGPT&Whisper APIs 등 (0) | 2023.03.06 |
|---|---|
| 2023/03/05: Generative AI landscape (0) | 2023.03.05 |
| 2023/03/02: ETL Tools, ViT, Dunning-Kruger effect, Foundation Model 용어의 기원 등 (0) | 2023.03.02 |
| 2023/02/28: Emerging ML Tech Stack 등 (0) | 2023.02.28 |
| 2023/02/27: AI 반도체 기술, 효과적인 Large AI 모델 빌딩하기 등 (1) | 2023.02.27 |